Тут буде шось типу бложика про те як іде розробка системи, яка комбінує генеративний ШІ та пошуковий двигун і яка буде працювати суто локально, на моєму власному ПК, без клаудів цих ваших.
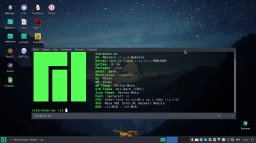
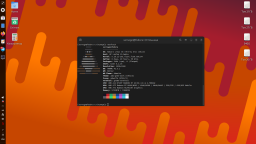
Завелось на старій відеокарті. Результати:
[CLBlast]
Processing Prompt (14 / 14 tokens)
Generating (200 / 200 tokens)
CtxLimit:214/4096, Amt:200/200, Init:0.00s, Process:6.98s (498.4ms/T = 2.01T/s), Generate:36.27s (181.3ms/T = 5.51T/s), Total:43.25s (4.62T/s)
[Vulcan]
Processing Prompt (14 / 14 tokens)
Generating (200 / 200 tokens)
CtxLimit:214/4096, Amt:200/200, Init:0.00s, Process:0.58s (41.4ms/T = 24.14T/s), Generate:19.31s (96.6ms/T = 10.36T/s), Total:19.89s(10.05T/s)```
На Vulcan працює швидше, ніж на OpenCL. Але все одно швидкість так собі. Схоже на чатжпт у годину пік, просто не запинається. Найбільш підходящими моделями виглядають meta llama 3.1 8b q4_0 та mistral 7b q4_0

Є свої нюанси. Але має запрацювати, якщо зробити наворочені промпти.
Блядь, походу, хтось вже це все реалізував.
Ну, пофігу, так навіть краще, можна користуватись інструментом, а не пиляти його.
Ну шо далі було, заїбав.